
Bezpieczeństwo danych nie zaczyna się od zakupu drogiego oprogramowania, tylko od zrozumienia, co naprawdę trzeba chronić i przed jakimi zagrożeniami. W praktyce chodzi o przetwarzanie danych osobowych w sposób, który ogranicza ryzyko wycieku, utraty i nadużyć. Poniżej rozkładam temat na konkretne elementy: od oceny ryzyka, przez techniczne i organizacyjne zabezpieczenia, aż po błędy, które najczęściej psują cały plan.
Najważniejsze rzeczy, które warto wdrożyć od razu
- Najpierw oceń ryzyko, a dopiero potem dobieraj narzędzia i procedury.
- Standardem powinny być szyfrowanie, wieloskładnikowe logowanie, aktualizacje i testowane kopie zapasowe.
- Same systemy nie wystarczą, jeśli uprawnienia, szkolenia i odpowiedzialności są chaotyczne.
- Chmura i praca zdalna wymagają kontroli urządzeń, dostępu i udostępniania plików.
- Zabezpieczenia trzeba regularnie sprawdzać, bo jednorazowe wdrożenie szybko traci wartość.
Najpierw trzeba wiedzieć, co chronisz
Ja zaczynam od prostego pytania: co w tej organizacji byłoby najgorsze, gdyby ktoś nieuprawniony zobaczył dane, zmienił je albo zablokował do nich dostęp? Właśnie z tej odpowiedzi wynika, czy potrzebujesz mocniejszego szyfrowania, ostrzejszej kontroli uprawnień, czy przede wszystkim lepszych procedur i szkoleń.
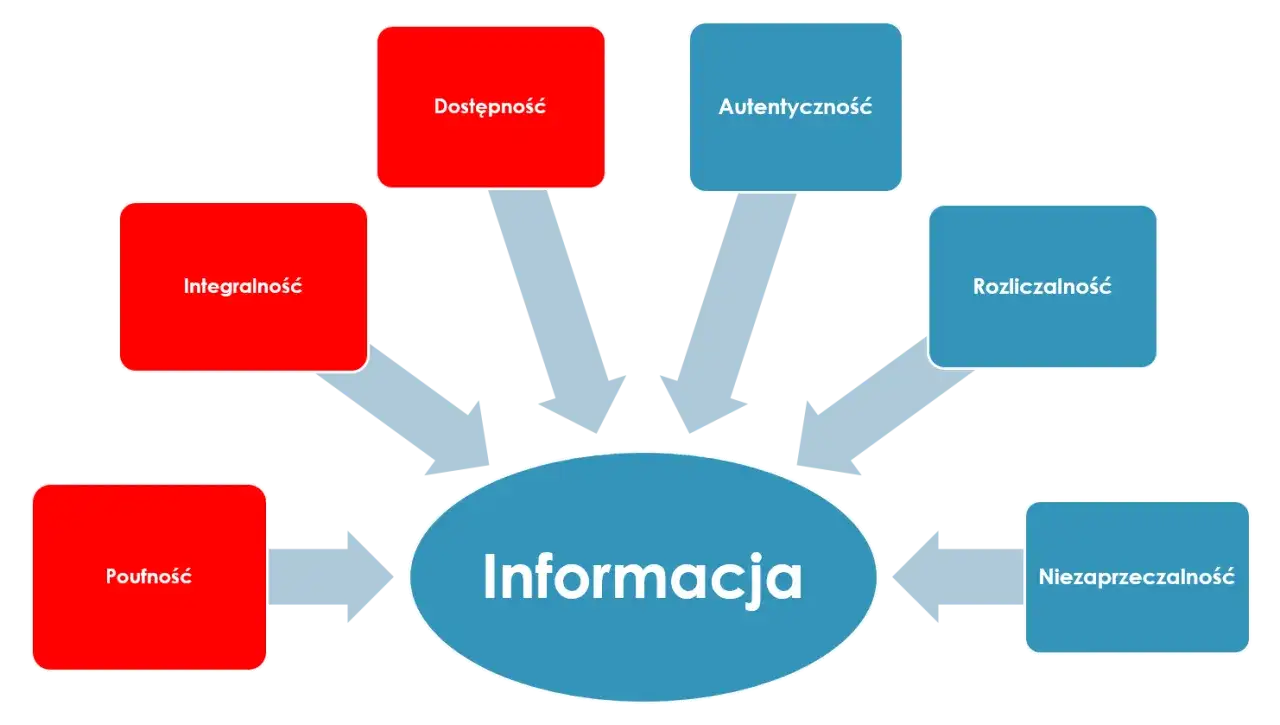
W ochronie danych liczą się trzy rzeczy, które często pojawiają się razem, ale nie znaczą tego samego:
- poufność - tylko uprawnione osoby mają dostęp do informacji,
- integralność - dane nie są niepostrzeżenie zmieniane, uszkadzane ani podmieniane,
- dostępność - można z nich skorzystać wtedy, kiedy są potrzebne.
Do tego dochodzi jeszcze odporność systemów i rozliczalność, czyli zdolność pokazania, że zabezpieczenia nie są przypadkowe. To ważne szczególnie w środowiskach technologicznych, gdzie dane krążą między CRM-em, pocztą, chmurą, helpdeskiem i urządzeniami mobilnymi. Gdy te przepływy nie są opisane, bezpieczeństwo zwykle jest tylko deklaracją, a nie realnym stanem. Od tego miejsca naturalnie przechodzi się do pytania, jak dobrać środki do skali i rodzaju ryzyka.
Ryzyko powinno prowadzić wybór zabezpieczeń
RODO nie wymaga jednego sztywnego zestawu zabezpieczeń dla wszystkich. Wymaga podejścia adekwatnego do ryzyka, czyli takiego, które uwzględnia charakter danych, zakres przetwarzania, kontekst, cele i koszt wdrożenia. Innymi słowy: inny poziom ochrony ma mała baza kontaktów marketingowych, a inny system kadrowy, panel medyczny albo platforma z dostępem z wielu krajów.
Patrzę na to przez kilka pytań, które warto zadać przed zakupem lub konfiguracją narzędzi:
| Czynnik | Na co patrzę | Co zwykle z tego wynika |
|---|---|---|
| Rodzaj danych | Czy są zwykłe, finansowe, pracownicze albo szczególnie wrażliwe | Im większa wrażliwość, tym mocniejsze szyfrowanie, kontrola dostępu i monitoring |
| Skala | Ilu osób dotyczą dane i ile systemów je obsługuje | Większa skala wymaga automatyzacji, logów i regularnych przeglądów uprawnień |
| Środowisko | Biuro, chmura, urządzenia mobilne, praca zdalna | Potrzebujesz ochrony końcówek, polityk urządzeń i silnego uwierzytelniania |
| Skutek incydentu | Co się stanie po wycieku, utracie lub zaszyfrowaniu danych | Kluczowe stają się kopie zapasowe, odtwarzanie i plan reakcji |
| Zależność od dostawców | Czy korzystasz z SaaS, hostingu, integratorów lub podwykonawców | Trzeba sprawdzić umowy, audyt i łańcuch dalszych podmiotów |
To właśnie dlatego projektowanie ochrony od początku ma sens. Privacy by design, czyli projektowanie zabezpieczeń już na etapie planowania procesu, zwykle wychodzi taniej niż łatanie systemu po incydencie. W praktyce dużo częściej psuje się nie technologia, tylko założenie, że „u nas to raczej nie nastąpi”. Z tego miejsca przechodzę do konkretnych narzędzi, które powinny być standardem, a nie dodatkiem.
Techniczne zabezpieczenia, które naprawdę podnoszą poziom ochrony
UODO podkreśla, że zabezpieczenia nie mogą być jednorazowym wdrożeniem. Trzeba je sprawdzać, aktualizować i testować, bo inaczej nawet poprawnie skonfigurowany system po kilku miesiącach może mieć dziury, których nikt nie zauważył.
W praktyce najwięcej dają rozwiązania, które chronią dane na kilku poziomach naraz:
- Szyfrowanie - obejmuje dyski, bazy danych, kopie zapasowe i transmisję. Bez zarządzania kluczami to połowa rozwiązania, więc klucz też musi być chroniony.
- Wieloskładnikowe uwierzytelnianie - szczególnie dla kont administracyjnych, poczty, VPN, CRM i paneli chmurowych. Samo hasło to dziś za mało.
- Aktualizacje i wsparcie producenta - system bez wsparcia producenta obniża poziom bezpieczeństwa szybciej, niż wielu administratorów zakłada.
- Kopie zapasowe - najlepiej według zasady 3-2-1, czyli trzy kopie, na dwóch nośnikach, z jedną poza głównym środowiskiem. Najważniejszy test to nie samo wykonanie backupu, ale odtworzenie danych.
- Logi i monitoring - pozwalają zauważyć nietypowe logowania, eksporty danych albo masowe zmiany rekordów.
- Pseudonimizacja - zastępuje część identyfikatorów kodami, co ogranicza skutki wycieku, zwłaszcza w środowiskach testowych i analitycznych.
- Segmentacja i kontrola dostępu - ogranicza ruch boczny w sieci i zmniejsza ryzyko, że jeden przejęty login otworzy dostęp do wszystkiego.
Najbardziej niebezpieczne jest traktowanie tych elementów jak checklisty do odhaczenia. Zgubne bywa zwłaszcza poleganie na jednym mechanizmie, na przykład samym haśle, samym antywirusie albo samych kopiach bez testu odtworzenia. Właśnie tu najczęściej wychodzi, czy organizacja ma realną odporność, czy tylko dobrą narrację. Sama technologia jednak nie wystarczy, jeśli ludzie i procesy działają chaotycznie, więc kolejny krok dotyczy organizacji pracy.
Organizacja pracy często decyduje o sukcesie bardziej niż narzędzia
W firmach, które dobrze radzą sobie z ochroną danych, największą różnicę robią zwykle rzeczy mało widowiskowe: porządek w uprawnieniach, jasne role i regularne przeglądy. Jeśli ktoś odchodzi z firmy, jego dostęp powinien zniknąć od razu, a nie „przy okazji”. Jeśli ktoś zmienia stanowisko, zakres uprawnień musi się zmienić razem z obowiązkami.
Najważniejsze elementy organizacyjne, które warto mieć pod kontrolą, to:
- minimalne uprawnienia - każdy dostaje tylko to, co naprawdę potrzebne do pracy,
- oddzielenie ról - osoba zatwierdzająca nie powinna jednocześnie wykonywać wszystkich krytycznych operacji,
- szkolenia praktyczne - nie jednorazowe slajdy przy onboardingu, tylko krótkie i regularne przypomnienia,
- procedury incydentowe - kto izoluje konto, kto zabezpiecza logi, kto kontaktuje administratora i prawnika,
- audyt dostawców - szczególnie tam, gdzie dane trafiają do podmiotów przetwarzających lub narzędzi SaaS,
- dokumentacja - bez niej trudno wykazać, że zabezpieczenia są spójne i aktualne.
Ja szczególnie pilnuję momentów wejścia i wyjścia pracownika z organizacji, bo właśnie tam powstaje sporo błędów. W praktyce nie chodzi o rozbudowaną biurokrację, tylko o to, żeby każdy wiedział, co robić i kiedy. To prowadzi do kolejnego obszaru, czyli pracy z chmurą i zdalnym dostępem, gdzie ryzyko rozjeżdża się najszybciej.
Chmura, SaaS i praca zdalna wymagają osobnych reguł
W środowiskach technologicznych dane bardzo rzadko siedzą w jednym miejscu. Są w aplikacji SaaS, na laptopie, w telefonie, w integracji API i w kopii zapasowej dostawcy. Dlatego nie wystarczy powiedzieć, że „system jest w chmurze, więc jest bezpieczny”. Bezpieczeństwo zależy od konfiguracji, odpowiedzialności i kontroli dostępu.
Jeśli pracujesz z chmurą albo zespołem rozproszonym, zwróć uwagę na kilka spraw, które realnie robią różnicę:
- zarządzanie urządzeniami - szyfrowanie dysków, blokada ekranu, zdalne czyszczenie i kontrola aktualizacji,
- warunkowy dostęp - logowanie tylko z zaufanych urządzeń, lokalizacji lub zgodnych poziomów ryzyka,
- kontrola linków i udostępnień - wygasanie odnośników, ograniczenia pobierania i rejestrowanie dostępu,
- oddzielenie kont prywatnych i służbowych - mieszanie ich zwykle kończy się przypadkowym udostępnieniem pliku,
- umowy i podpowierzenie - trzeba wiedzieć, kto jeszcze może mieć dostęp do danych i w jakim kraju są przetwarzane,
- plan wyjścia od dostawcy - eksport danych, ich usunięcie i sprawdzenie, czy kopie nie zostają „na zawsze”.
W projektach, które analizuję, to właśnie brak dyscypliny w chmurze najczęściej tworzy iluzję kontroli. Z jednej strony wszystko wygląda nowocześnie, z drugiej jeden publiczny link albo źle skonfigurowane konto administracyjne potrafi zniwelować połowę pracy. Stąd już tylko krok do błędów, które widzę najczęściej w praktyce.
Najczęstsze błędy, które widzę przy wdrażaniu ochrony
Najgorsze w tych błędach jest to, że są banalne. Rzadko chodzi o wyszukany atak, częściej o brak konsekwencji w podstawach. Gdy coś ma się rozsypać, zwykle nie robi tego spektakularnie, tylko po cichu.
- Backup istnieje, ale nikt go nie odtwarza. Samo tworzenie kopii nie daje ochrony, jeśli nikt nie sprawdził, czy da się z nich szybko wrócić do działania.
- System działa po zakończeniu wsparcia producenta. To wygodne do czasu pierwszego poważnego incydentu, bo bez poprawek bezpieczeństwa ryzyko rośnie z każdym miesiącem.
- Jeden login krąży w zespole. Wtedy nie da się ustalić odpowiedzialności, a audyt staje się fikcją.
- Uprawnienia nie są odbierane. Stare konta i nadmiarowe dostępy to jeden z najprostszych sposobów na przypadkowy lub celowy wyciek.
- Szkolenie było raz i temat zamknięty. Ludzie zapominają, a zagrożenia się zmieniają, więc przypomnienia muszą wracać.
- Analiza ryzyka jest tylko plikiem w folderze. Jeśli nie prowadzi do konkretnych decyzji, nie chroni niczego.
UODO przypomina też, że w razie naruszenia administrator co do zasady ma 72 godziny na zgłoszenie sprawy do organu nadzorczego, a podmiot przetwarzający informuje administratora bez zbędnej zwłoki. To dobry test, czy procedura incydentowa naprawdę istnieje, czy tylko jest wpisana do dokumentacji. Z tego miejsca najrozsądniej przejść do priorytetów, bo nie wszystko trzeba robić naraz.
Od czego zacząć, gdy trzeba poprawić zabezpieczenia bez chaosu
Gdybym miał uporządkować ochronę od zera, zacząłbym od pięciu kroków. Najpierw krótka analiza ryzyka, potem szybkie wzmocnienie dostępu, następnie backupy i odtwarzanie, później porządek w uprawnieniach, a na końcu prosty plan reakcji na incydent. To nie jest efektowna lista, ale właśnie taka daje najszybszy zwrot.
- Wprowadzam wieloskładnikowe logowanie tam, gdzie dostęp do danych ma największe znaczenie.
- Szyfruję laptopy, nośniki i kopie zapasowe.
- Sprawdzam, czy systemy są wspierane i aktualizowane.
- Testuję odtworzenie danych z kopii, a nie tylko samo ich tworzenie.
- Porządkuję role, uprawnienia i procedurę zgłaszania incydentu.
To wystarczy, żeby z poziomu „mamy jakieś zabezpieczenia” przejść do poziomu, który realnie ogranicza szkody. Nie trzeba od razu budować rozbudowanego programu bezpieczeństwa na lata, ale trzeba zacząć od rzeczy, które faktycznie działają i które da się sprawdzić w praktyce. Jeśli ten fundament jest solidny, reszta staje się dużo łatwiejsza do utrzymania.